MVP Illustration
The term “Minimal Viable Product” - or more often just MVP - has become more and more used over the past decade. When explaining the concept I’ve often seen illustrations like this one:
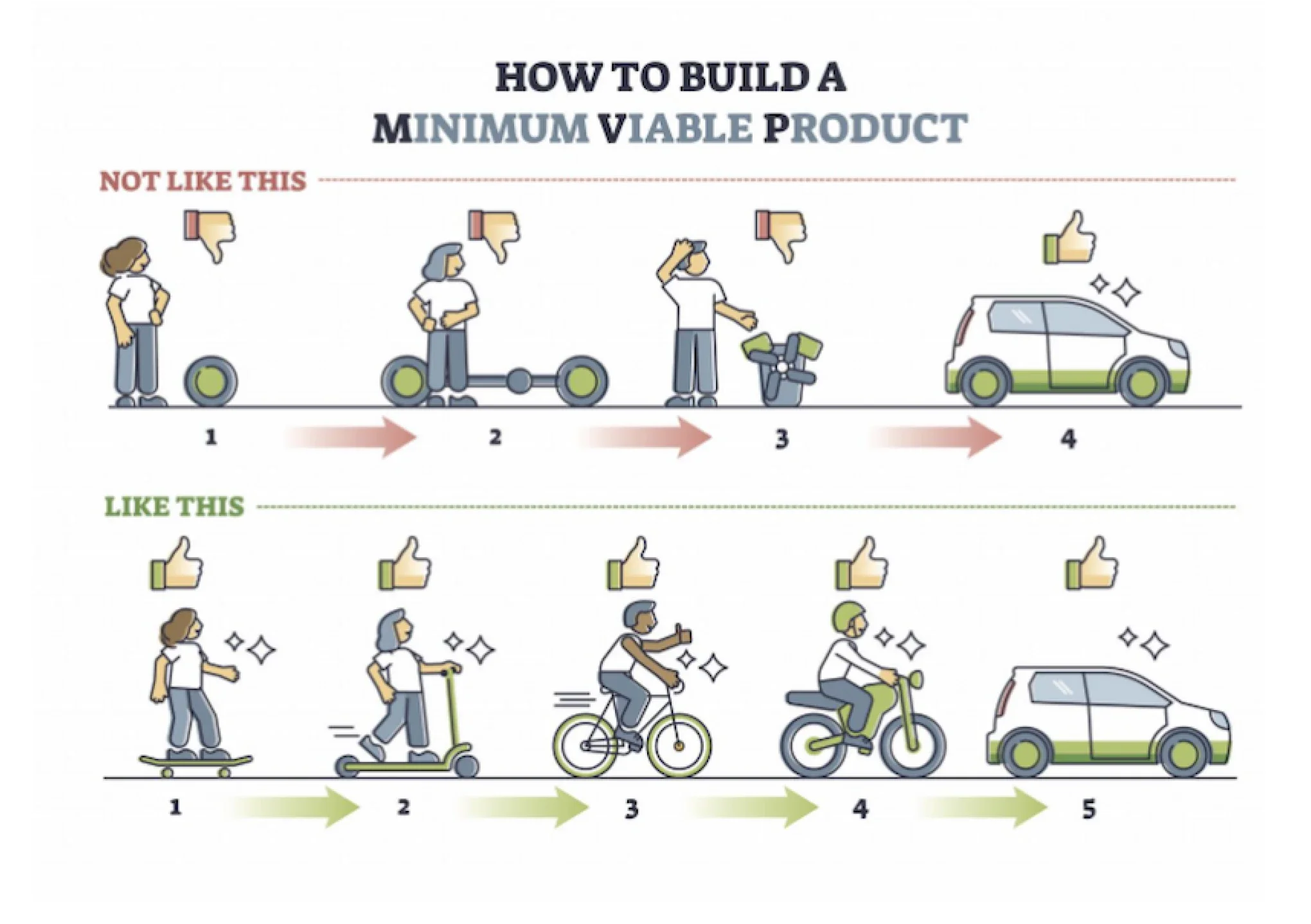
I do, however, think these are bad illustrations, as they bring the wrong message.
- The “Not like this” is fine to show that it’s not about building step by step - and not havig a usable product until the end.
- The “Like this” is, however, not providing the right illustration. It shows you can buy/make the wrong product 5 times until you get it right.
When I am applying MVP - I want to start with the Minimum Viable Product. I want to start with a usable (a viable product) and add features and capabilities to this - not rebuild it from scratch in every iteration. This is why after playing with an AI generator a bit I’ve come up with a better illustration I use to explain MVP which I thing is far better.